A new version of the build vs buy debate is happening in almost every go-to-market org right now. Someone in a planning meeting says, “we can probably build this ourselves” and the room either nods along or splits down the middle. If you’re in RevOps, you’ve heard it. You may have even said it.
And honestly? The instinct makes sense.
AI is table stakes
From Salesforce and Google to Notion and Canva, everyone has AI. Every platform your team already pays for is shipping AI features this quarter, and buyers know it. “We have AI” is not a differentiator anymore. It’s expected.
That shift is doing something interesting to how GTM teams think about their stack. When AI is everywhere, and access to capable models is essentially free, the obvious question becomes: why buy a platform when we can build exactly what we need?
Why the build argument has momentum right now
The barriers have never been lower. You can wire Claude or GPT into a workflow this week. MCP connectors are shipping across every major LLM. Your engineers aren’t intimidated by this anymore, and frankly, neither is your RevOps team.
Layer on top of that the exhaustion with tool sprawl. The average GTM team is managing somewhere between eight and ten tools, many of them overlapping, most of them underloved. The pitch of “add another platform” doesn’t exactly land with enthusiasm.
So when someone says “let’s just build what we need,” there’s a legitimate relief in that idea.
Fewer vendors. More control. A system that fits your motion instead of one you’re contorting your motion to fit.
The cost pressure is real, too. Budgets are tighter, headcount is flat or shrinking, and if your team can stitch together enrichment APIs, some LLM workflows, and a few webhooks, the math looks attractive. This is a coherent position that many smart teams are taking.
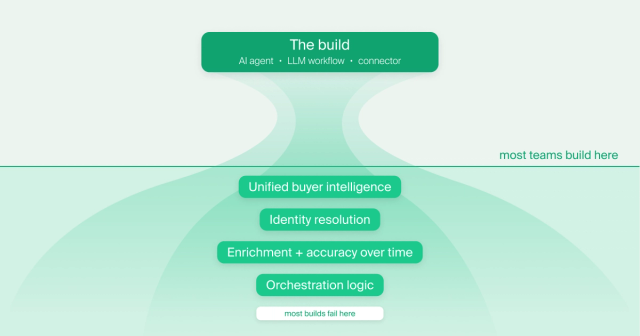
Where it breaks
Most teams clear the first hurdle without too much trouble. The agent runs, the outputs look reasonable, reps start getting recommendations. Then, quietly, it starts falling apart.
A rep ignores a recommendation because the account was already in an active sequence. Another sends a personalized email referencing a job title that changed three months ago. A third gets routed a "high intent" account that marketing has been nurturing for weeks. Nobody told the agent any of this.
The reps stop trusting it, the RevOps team starts fielding questions, and the experiment gets quietly shelved. None of that is a model problem. The model did exactly what it was told — it was just working from a fragmented, partially stale picture of the buyer. Garbage in, confidently-delivered garbage out.
Building the AI is the straightforward part. Building the foundation that makes it trustworthy is the hard part, and it’s almost always the part that gets skipped.
The question underneath the debate
AI makes it easier to build. It’s also getting harder to trust. And right now, almost every team is focused on the former while skipping what makes the latter possible.
The build vs. buy debate misses the point. The more important questions are whether your AI outputs will be trusted and whether they'll hold up at scale.
Businesses building GTM AI are focused on the model and the surface. What agent, what prompt, what workflow, what output? That’s the visible part of the work, and it’s where the energy goes. Almost nobody is asking what happens two layers down.
What does the agent actually see when it looks at a buyer? How complete is that picture? How accurate? How fresh? When the same person shows up as four different records across your systems, which one does the agent trust? The data is incomplete, the identity is unresolved, and the context is stale.
The teams that skip those questions will spend a lot of time debugging agent behavior that isn’t actually an agent problem.
The part the “build” plan usually skips
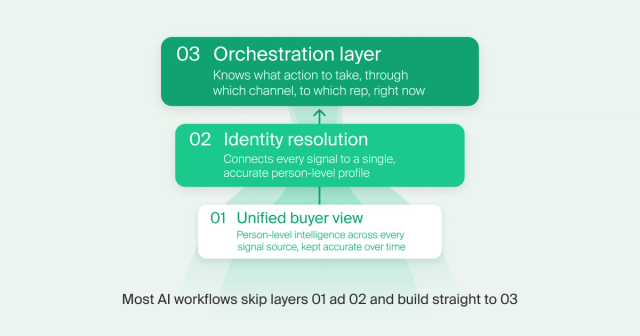
Three things have to be true for AI to work reliably in GTM:
A unified, continuously updated view of every buyer.
Not account-level records in a CRM. Person-level intelligence stitched together across every signal source, kept accurate over time. Most agents are running on a fraction of this picture and producing outputs that reflect it.
Identity resolution that actually works.
The same person shows up across your systems as multiple different records. Until those are connected into a single accurate profile, your AI is pattern-matching across fragments. That’s the root cause of most bad outputs: stale personalization, misfired routing, recommendations reps don’t trust.
An orchestration layer that knows what to do with the intelligence.
A signal firing is not the same as knowing what action to take, through which channel, to which rep, right now. Most teams have never formally solved that routing problem. They’ve duct-taped it with tools such as Clay or Zapier workflows and RevOps tickets.
Most teams building AI GTM workflows right now are solving for the model and the surface. They're skipping the foundation.
This is exactly what Common Room is built on. The intelligence foundation that makes AI actually work in GTM.
- A complete, trusted picture of every buyer. Common Room unifies buyer identity across every signal source and presents it to AI agents in a format optimized for accuracy and completeness of context. Not a sampled slice of CRM data — every person, every org, every signal, continuously updated and enriched over time.
- Orchestration logic that knows what to do with it. The Revenue Control Plane handles the routing of what action to take, through which channel, to which rep, so teams aren't building and maintaining that logic themselves.
- AI that shows up where work already happens. Because it's all embedded into the surfaces where reps already operate, the intelligence gets used. No new tool to adopt, no behavior change required.
What this means right now
For RevOps, this is the moment to get ahead. The building is already happening and most of it is creative and well-intentioned. Some of it will create a cleanup problem nobody budgeted for.
Avoiding that outcome isn't about slowing the building down. It's about asking a harder question first: what is this actually running on?
A few things worth pressure-testing before the next workflow goes live:
When your AI agent looks at a buyer, what does it actually see?
If the answer is “whatever’s in Salesforce,” you’re running AI on maybe 10% of the picture. The job changes, the product usage spikes, the community signals, the champion who just moved companies — most of that never makes it into the CRM.
How confident are you in the contact data flowing into your AI tools?
Not “we have ZoomInfo” confident. Actually confident. Stale enrichment data doesn’t become less stale when you put an agent on top of it.
Who owns the orchestration logic?
When a high-intent signal fires today, what decides whether it becomes an SDR call, an AE email, or a marketing nurture? If the answer is a Zapier workflow that one person built and nobody fully understands, that’s your bottleneck. Adding more AI on top of it won’t fix it.
The teams that win the next few years won't necessarily have the most sophisticated models or the most creative prompts. They'll have the clearest, most complete and trusted picture of their buyer, and an intelligence foundation that AI can actually operate on. Not a fragmented stack of enrichment vendors, stale CRM records, and disconnected signal sources held together with good intentions.
Build all you want. Just make sure you're building on something real.