
For our latest Data Brown Bag series, we hosted a discussion on natural language processing (NLP) with Ashish Bansal, a leading authority in NLP and recommendation systems. Ashish shared some fascinating insights on how to unlock peak performance from large-scale language models (LMMs) to fuel advanced NLP. He talked about his experiences working at Capital One, Twitter, Twitch/Amazon, and his own startups, as well as from his book Advanced Natural Language Processing with TensorFlow 2.
At Common Room, we believe data and AI are needed to build strong communities. NLP gives companies the ability to extract valuable insights from the large volumes of community conversations that happen on an ongoing basis. It is an essential part of intelligent community growth, or the practice of using technology to drive the scale and success of a community.
Below are the key takeaways from our conversation with Ashish about NLP and LLMs.
What are large-scale language models, and why are they useful for natural language processing?
LLMs are deep learning models such as PaLM, GPT-3, BERT, and Bloom that are trained on large datasets with billions of parameters that can be independently changed and optimized. The unique part about these models is they enable few-shot and zero-shot learning for solving language challenges such as language translation, entity recognition, summarization, and Q&A.
We have seen huge success and applications of LLMs in the area of natural language processing, especially with the widespread availability of tools like GPT-3 and Hugging Face that do not require domain experts to apply these models to use cases.
More details about LLMs can be found in How Large Language Models Will Transform Science, Society, and AI (Standford) and The emerging types of language models and why they matter (TechCrunch).
Current challenges in LLM computations
The picture below shows the timeline and exponential growth in the number of parameters for many of the state-of-the-art (SOTA) LLMs, with the latest being Microsoft’s Turing-NLG which was trained on 530 billion parameters. To create these SOTA LLMs, companies have been using increasingly large amounts of computing power.
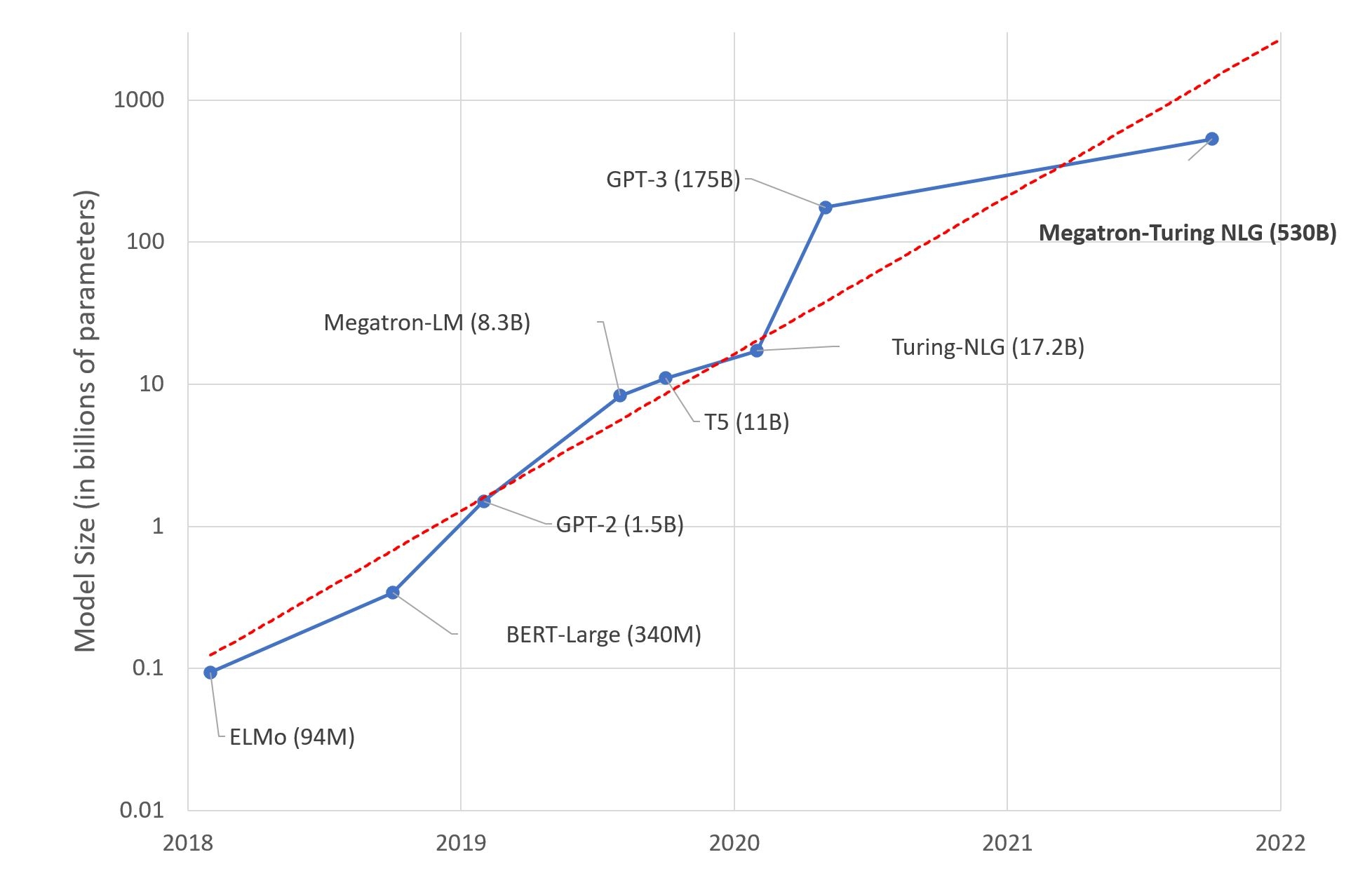
In fact, the model size and compute requirements for SOTA LLMs are growing faster (10x per year) than Moore’s Law (2x every two years), which is predicted to end sometime in the 2020s, according to MIT Technology Review. We are quickly approaching the limit of the number of transistors we can pack in a chip, so continuing to advance LLMs will require some creative problem solving.
How to address computing limitations in building SOTA models
To keep pushing the capabilities of what LLMs can do while keeping in mind limitations like Moore’s Law, we must ask ourselves: “Is the only solution to increase the number of parameters with more layers and training datasets? Or are there other modifications that can be used to build SOTA models?”
Here are a few innovative techniques that can be used to build sophisticated SOTA models within the boundaries of modern computing.
Break down the training into two steps
Hierarchical representation and processing of features is the basis of all deep learning. This lends itself well to language and image processing tasks and aligns with the way our brain processes information. The main ideas behind hierarchical representation are articulated very well in Yan Lecunn’s talk The Unreasonable Effectiveness of Deep Learning.
Due to their layered structures, these new LLMs can easily break the traditional training process into two steps:
- Pre-training where the lower layers of the models are trained on large corpora of text in the order of billions or trillions of data points for basic language tasks, such as next word prediction.
- Fine-tuning in which the model is trained for more specific tasks such as sentiment analysis, Q&A, and language translation. This second step requires significantly fewer examples (even a few hundred) thanks to the first step.
More details about these processes can be found in Language Models are Few-Shot Learners (Cornell) and The Natural Language Decathlon: Multitask Learning as Question Answering (Cornell).
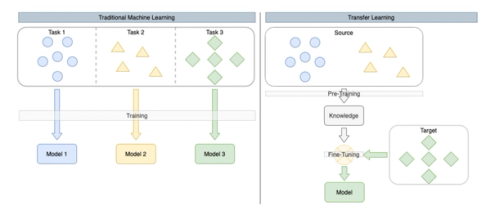
Diagram highlighting the differences between traditional machine learning and transfer learning-based models
Tokenization and handling out-of-vocabulary words
Tokenization entails splitting a sentence into constituent tokens that may be words, characters, or subwords. The model learns from the representation of the tokens. This representation allows mathematical operations to be performed on tokens. A core innovation of BERT was using wordpiece (or byte-pair encoding) tokenization scheme which provides efficient representation of words in bounded space. Cons include the fact that tokenization is a language-specific solution and it is not a solved problem for certain languages such as Japanese.
Truncation schemes for long text
Although many models can handle long texts, it is only prudent for memory and processing reasons to give the texts that would be the most useful and achieve the same performance from the model. This is domain-specific, and depends on the problem we are trying to solve. For example, on a task of deducing sentiments from customer reviews or feedback, one of the ways we can truncate the data is use the last sentence of the review as people tend to summarize their reviews toward the end.
Learning rate annealing
One of the key parameters to optimize training in deep learning or any machine learning is making changes to the learning rate which determines how the gradient descent traverses the optimization function. A small learning rate means a larger time for the model to run. In terms of deep learning, we are talking about hundreds of thousands of epochs and days of learning.
There are several optimization techniques suggested in learning rate: One of them is starting from a large learning rate and going to smaller learning rate and other is cosine scheduled learning rate as discussed ub the article Exploring Stochastic Gradient Descent with Restarts (SGDR). This helps reset the learning rate every few epochs so the system can get out if it’s stuck in a local minima.
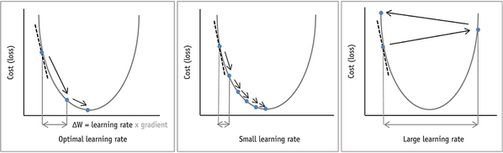
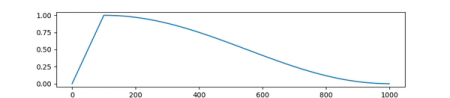
Cosine scheduled learning rate. Source: Hugging Face
Data and AI are critical for intelligent community growth
Without some of the modifications discussed above, beating SOTA benchmarks may not be possible. An additional benefit of these tips and tricks is that they can be applied when building LLMs in enterprises of any size.
At Common Room, we firmly believe data is one of the critical components that will continue to unlock our platform’s truest potential for our customers and the communities they build, nurture, and support. We have a multi-pronged approach toward using data and AI that ensures we'll continue to grow efficiently while offering increasingly powerful insights to community and company leaders so they can delight their members.
More details on our AI efforts can be found in the blog Common Room’s Data and AI pillars for building strong communities.
Want to see our data team’s work in action? Request a demo or request a demo to learn more about intelligent community growth.