
Your CRM isn't broken. It's just describing a world that no longer exists.
The VP of Engineering you're targeting? She left that company eight months ago. The lead score you're acting on? Built on enrichment data that was accurate when it was pulled, but hasn't been touched since.
This is CRM data decay. And it's not a hygiene failure. It's a structural problem with how revenue teams have been taught to think about their data.
Most teams respond by running cleanup projects, buying another enrichment vendor, or setting rules that break quietly every time their data model changes. None of it solves the underlying issue: the world keeps moving, and your CRM doesn't.
What is CRM data decay?
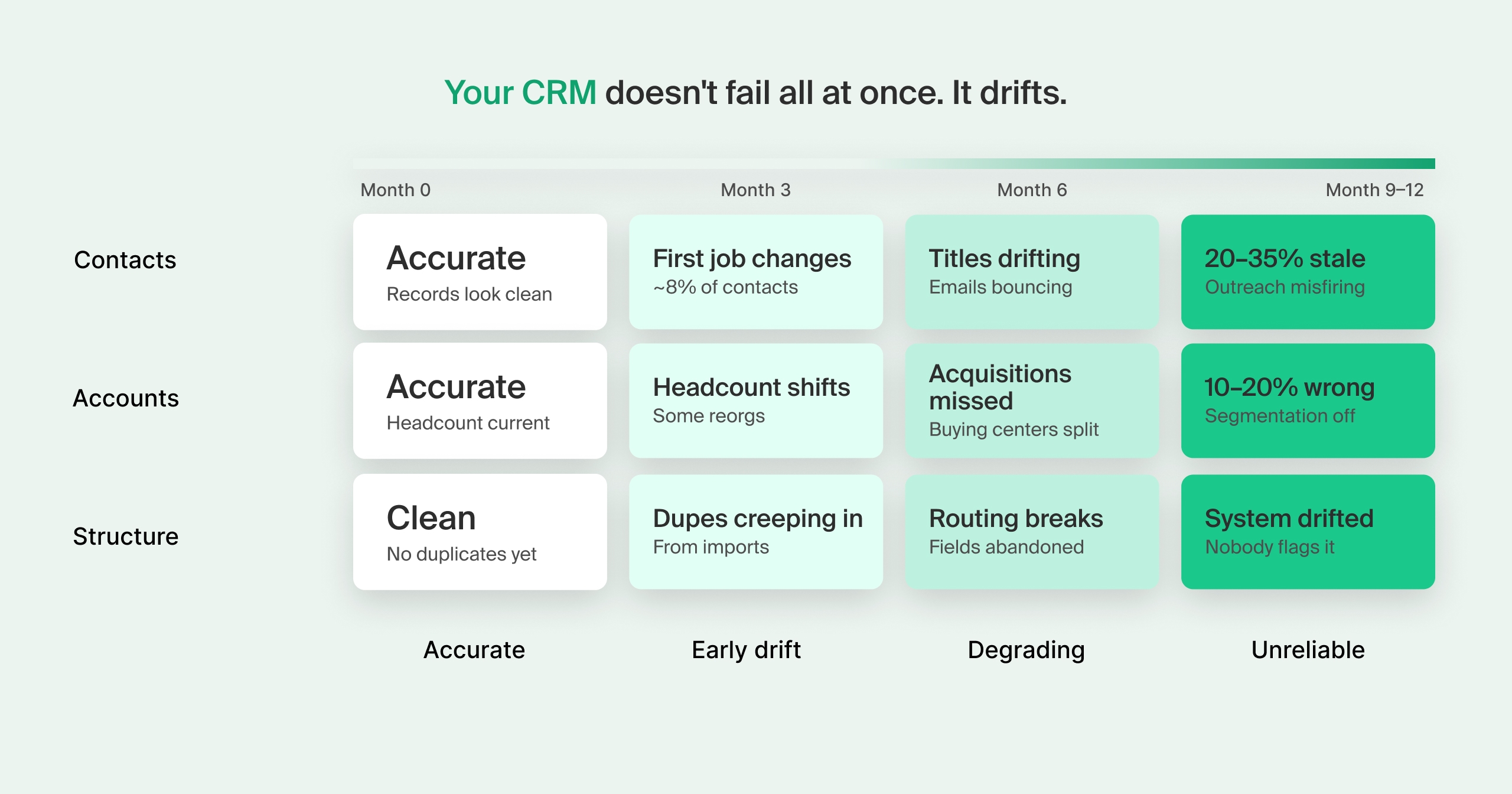
CRM data decay is the gradual degradation of contact and account records over time as real-world information changes, but your system doesn't update to reflect it.
The most obvious form is contact-level decay: people change jobs. According to LinkedIn, professionals today are on pace to hold twice as many jobs over their careers compared to 15 years ago, which means the contact you enriched six months ago has a reasonable chance of being wrong right now.
It’s unsurprising, then, that a contact list that was accurate at the start of the year can be meaningfully wrong by Q3. Not because anyone failed to maintain it, but because change is continuous and data capture isn't.
What CRM data decays and how fast?
Not all data decays at the same rate. According to CRM quality benchmarks:
- Email addresses decay at 3.6% per month (around 30-40% annually)
- Job titles shift at 25-35% per year
- Company data (headcount, structure, ownership) changes at 10-20% annually
The fields your reps rely on most for outreach are the ones going stale the fastest.
Account-level decay is harder to catch. Companies get acquired, org structures change, and headcounts swing. What your CRM has on file for an account may be a year or more behind what's actually true.
Then there's structural decay: duplicates from enrichment imports, routing rules nobody updated, fields that exist because someone needed them once. No single record is obviously wrong. The system has just quietly drifted from how you actually operate.
Why enrichment alone doesn't fix it
The conventional response to bad CRM data is to buy more enrichment. Run a ZoomInfo export. Push a Clay waterfall. Refresh the records and call it done.
This misunderstands the problem.
Enrichment adds data. It doesn't continuously reconcile data against reality. When you enrich a record, you're getting a snapshot: accurate as of the moment the enrichment provider last crawled that source. The moment you push that data into your CRM, the clock starts ticking again.
The other issue: enrichment doesn't resolve the records you already have. If a contact exists three times under different emails, enriching those records gives you three freshly enriched duplicates.
The teams outperforming their peers on this aren't running better enrichment cadences. They're treating CRM accuracy as an ongoing system.
Enrichment tells you what's true right now. It doesn't tell you what's changed since last time — or fix the structural mess underneath.
What CRM data decay actually costs you
The cost of bad CRM data rarely shows up as a data problem. It shows up as a performance problem.
Reps working bad accounts
When contacts are outdated, reps are reaching out to people who no longer have buying authority. When accounts are duplicated or miscategorized, prioritization logic breaks. Reps chase the wrong things and miss the right ones.
AI that makes confident mistakes
Every AI workflow in your GTM stack—prioritization agents, outreach generators, signal surfacing—depends on the CRM being accurate. AI built on fragmented, outdated data doesn't produce bad-looking outputs. It produces confident-sounding outputs that send teams in the wrong direction. That's worse.
RevOps maintaining, not enabling
When your RevOps team spends its cycles cleaning up duplicates, reconciling contradictory records, and patching enrichment gaps instead of building the automation and reporting the business needs, that's a structural cost. It compounds.
Signals that never fire
If an account shows strong buying signals but the contact records are wrong (wrong person, stale title, wrong company), the signal can't route to the right rep. Signal-based GTM only works if the identity layer underneath it reflects reality.
Why this keeps happening
The core problem is architectural. Most GTM teams built their CRM processes around data entry, not data maintenance. The system was designed to capture information at a moment in time. Nothing was built to continuously compare that captured information against what's actually true.
Periodic cleanup projects can reduce the mess, but they're inherently behind. By the time you've cleaned last quarter's data, this quarter's decay has already started. Rules-based systems help, but only for the patterns you anticipated.
There's also an organizational dynamic at play. Data quality is everyone's problem and nobody's job. RevOps doesn't have time for continuous cleanup. Sales doesn't update records they don't trust. Marketing doesn't want to suppress contacts that might convert. The CRM gets worse, slowly, until it fails loudly.
What continuous CRM accuracy looks like
Solving CRM data decay requires shifting from a cleanup model to a continuous maintenance model. The difference is as much philosophical as it is operational.
If 15-20% of your data degrades every quarter and you clean it once per quarter, you're maintaining data that was accurate for roughly two weeks out of every thirteen.
A continuous model treats CRM accuracy as a system that runs alongside your GTM motion. One that identifies drift as it happens and surfaces what needs attention before it creates downstream problems.
In practice, the difference shows up in a few specific ways:
Job change monitoring that runs automatically, not on a schedule
When a key contact changes roles, your team needs to know within days, not at the next quarterly audit. The window for acting on a job change closes fast.
Duplicate detection that happens before records compound
Every enrichment push, every tradeshow import, every form fill is an opportunity to create another duplicate. A continuous system catches these at the point of entry rather than after you've got three versions of the same contact with conflicting data across all of them.
Prioritized cleanup, not just a flagged list
One of the reasons cleanup projects stall is that they produce enormous lists with no clear starting point. A useful system tells you what to fix first i.e. which records are actively being used in outreach or which accounts have open opportunities attached.
History preserved through cleanup
Merging records or updating a contact shouldn't mean losing the activity and relationship context attached to the original. That context (past conversations, engagement history, account association) is often more valuable than the corrected field.
The goal isn't a clean CRM at a point in time. It's a CRM that stays aligned with reality continuously, so your team isn't making decisions based on a version of the world that stopped being true six months ago.
How Common Room approaches this
Common Room's DataAgent is built for this problem specifically. It's a data intelligence agent that continuously identifies CRM records that no longer reflect reality — outdated contacts, duplicate contacts, and duplicate accounts — and organizes them into actionable cleanup workflows.
The approach is different from rules-based cleanup tools for a specific reason: it doesn't require you to define what bad data looks like before the system can help. DataAgent surfaces what needs attention using Common Room's understanding of identity, job-change detection, and CRM context, then shows your team what to fix and why.
That matters because most teams don't know exactly what their data problems are until they try to act on the data. DataAgent flips that. You see what's wrong before it costs you a deal, not after.
Cleaning records also doesn't mean losing history. DataAgent is designed to preserve activity, relationships, and account context during cleanup — because a clean record that's lost its relationship history isn't actually useful.
The result is a CRM your team can trust in practice. And a stronger foundation for every signal-based GTM workflow built on top of it.
The bottom line
CRM data decay is a structural problem. The world keeps changing. Your data capture doesn't. And the gap between what your CRM says is true and what's actually true gets wider every quarter you don't address it.
More enrichment narrows that gap temporarily. Periodic cleanup projects reset it to a lower baseline. Neither keeps pace with the rate of change in your market.
The teams closing that gap consistently are treating CRM accuracy as a continuous system, not a recurring project. Your GTM motion is only as good as the reality it's working from.